Overfitting
Nella sezione introduttiva abbiamo visto come funzionano (per sommi capi) le reti neurali allenate con il deep learning. Tuttavia, quando si fecero i primi test per verificare la correttezza del procedimento, si presentarono anche diversi problemi. Uno dei più frequenti viene detto ovefitting.
Quando si procede ad allenare una rete neurale, si usano due diversi gruppi di input: il gruppo di dati di allenamento, usato per sistemare i parametri della rete, e il gruppo di test, usato per verificare l'accuratezza del lavoro della rete. L'overfitting avviene quando la rete, invece di imparare a generalizzare sui dati di allenamento (e quindi comprendere ciò che sta facendo), si limita ad imparare a memoria tali dati, avendo quindi degli scarsi risultati quando si tratta di vedere i suoi progressi sui dati di test. La sua accuratezza smette di crescere nel tempo ed inizia ad oscillare o a diminuire. E questo è un problema, in quanto noi vogliamo massimizzare tale accuratezza.
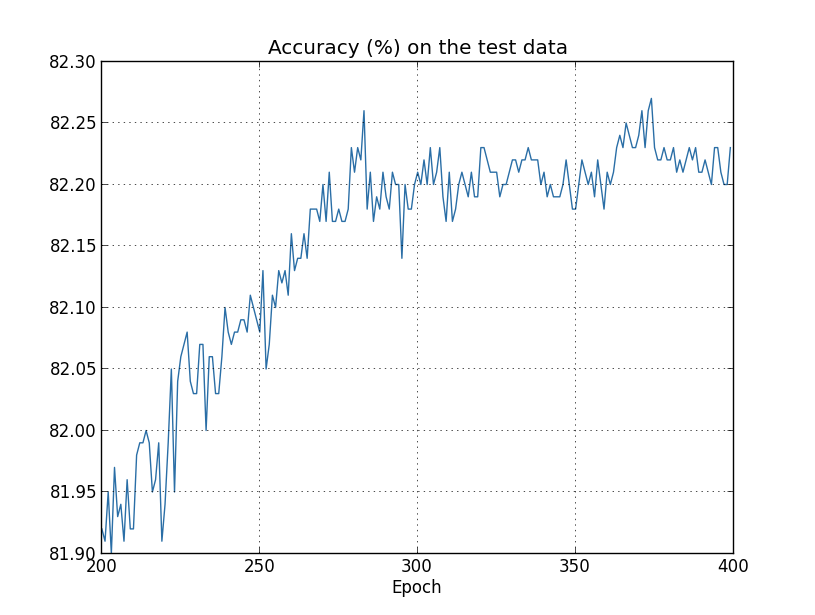
Il grafico dell'accuratezza nel classificare delle cifre scritte a mano da parte di una rete neurale. Si può notare come a partire dall'epoca 280, il trend in crescita si ferma e la precisione inizia ad oscillare.
L'overfitting quindi impedisce alla nostra rete di imparare correttamente: il nostro obiettivo è quindi individuare il momento in cui inizia tale fenomeno per evitare che la rete si sovraalleni.
Un modo per farlo è proprio tenere traccia dell'accuratezza sui dati di test mentre la rete si allena: così, quando vediamo che essa cessa di migliorare, fermiamo l'allenamento della rete. Anche se questo potrebbe non essere segno di overfitting, tale procedimento lo previene per certo.
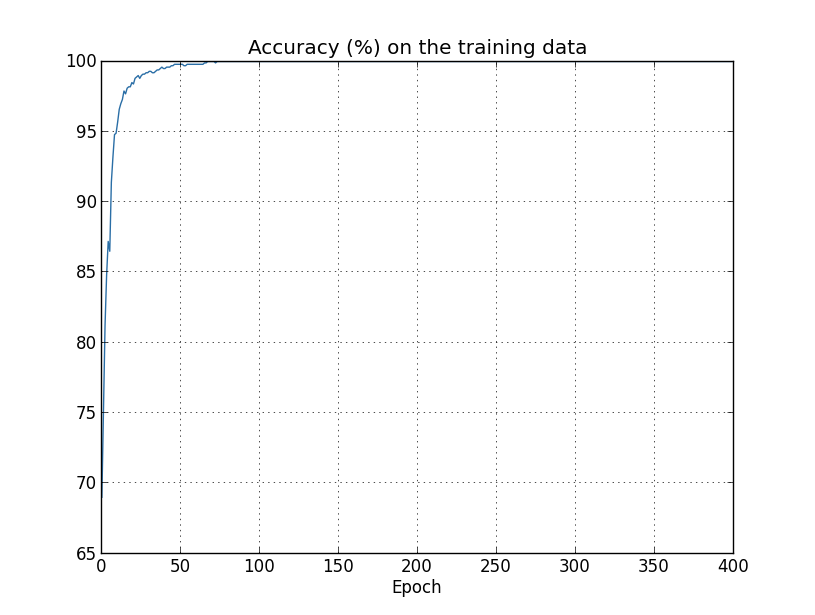
Il grafico dell'accuratezza nel classificare delle cifre scritte a mano da parte di una rete neurale sui dati di allenamento. Ben presto, la rete inizia a memorizzare le peculiarità di tali dati, riconoscendoli non perché ha realmente capito, ma solo perché si ricorda a memoria tutto il set di dati.
Un altro metodo per individuare l'overfitting è misurare l'accuratezza su un set di dati chiamato di validazione alla fine di ogni epoca, in modo da poter riconoscere quando la rete smette di migliorare la propria performance e fermare il processo di allenamento (tale metodo è anche detto early stopping). Il set di validazione è una parte dei dati che si trova a metà tra quelli di allenamento e quelli di test: si tratta di dati presi dal set di allenamento, ma usati per testare la rete in modo veloce, con l'unico scopo di individuare l'overfitting, senza entrare nei dettagli delle prestazioni della rete. Il set di validazione è anche usato, più in generale, per confrontare le prestazioni della rete per diversi valori dei parametri secondari (come, ad esempio, si può determinare quale valore del tasso di apprendimento sia il migliore).
Ma perché scegliere di usare i dati di validazione al posto di quelli di test sia per l'overfitting che per i parametri secondari? Se usassimo il set di test, rischieremmo di causare l'overfitting dei nostri parametri su tali dati, poiché sarebbero validi solo per le peculiarità del set di test e la nostra rete non funzionerebbe con altri set di dati. Usando invece il set di validazione, possiamo decidere i parametri e poi valutarli con i dati di test. Questo procedimento è detto di held out, in quanto i dati di validazione sono scelti tra quelli di allenamento.
Un ultimo modo per ridurre l'overfitting è quello di aumentare il numero di dati usati per l'allenamento della rete. Con un buon set di dati di allenamento, anche le reti più grandi hanno meno probabilità di sovraallenarsi. Tuttavia, non sempre è possibile ampliare il set di allenamento e spesso ampliarlo è un procedimento costoso, tanto da renderlo inattuabile in molte situazioni.
In realtà, esiste un altro metodo, che tuttavia non vediamo in questo paragrafo: prende il nome di regolarizzazione.